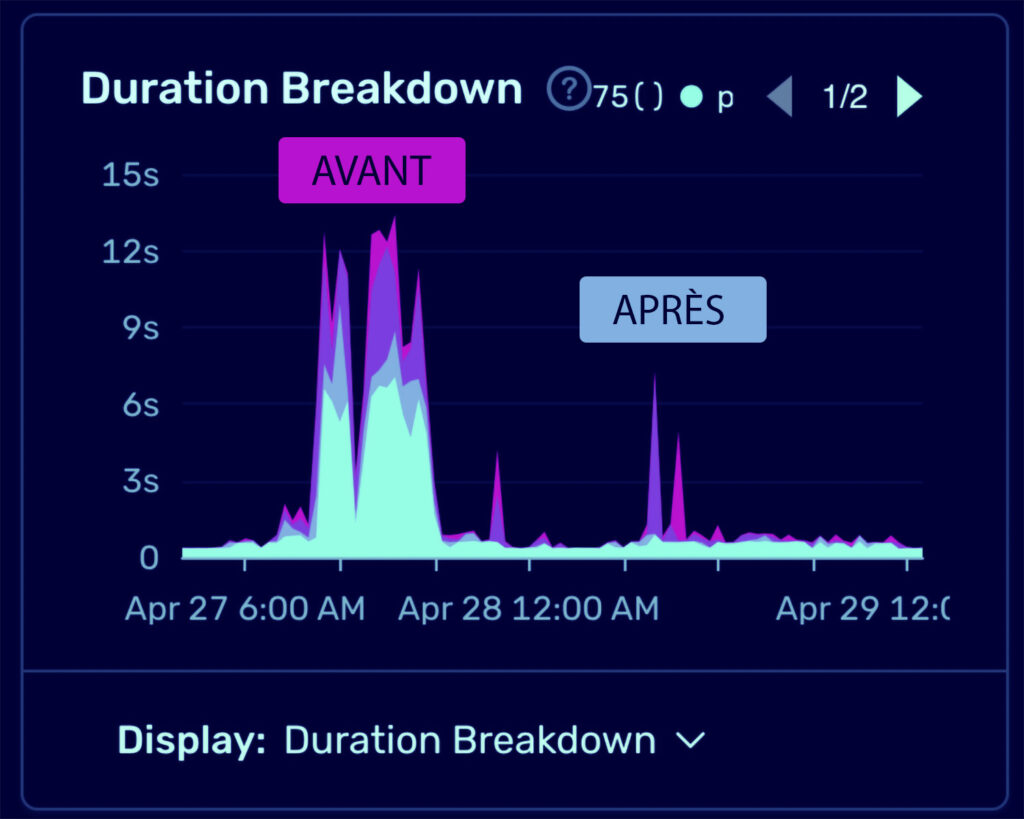
Il y a peu de magie dans notre travail, mais on partage un de nos tours préférés, sur les bases SQL : quand le client nous appelle à l’aide “j’ai une requête sur ma base de données qui met 45 secondes”. Quelques heures plus tard, la même requête est descendue en dessous d’une seconde, cela paraît instantané. Et ce n’est pas tout : la mémoire et le processeur du serveur sont beaucoup moins sollicités, car la quantité de données à brasser est beaucoup plus légère. Du coup on réduit l’engorgement et toutes les autres requêtes sont accélérées. Le client peut légitimement se demander quel sortilège se trouve derrière tout ça.
Ce n’est pas un problème au début des projets, lorsque le volume de données reste raisonnable. Mais c’est du quotidien avec des clients ambitieux : dès qu’une base de données contient des dizaines de milliers de lignes, elles-mêmes reliées à plusieurs tables relationnelles, les combinaisons contiennent des millions de colonnes, la mémoire sature, le disque dur prend le relais, les files d’attentes de requêtes se créent, le réseau est obstrué, et les serveurs suffoquent. L’optimisation peut avoir des effets miraculeux, en tout cas les clients sont généralement sonnés de voir qu’on peut diviser par 100 le temps de chargement d’une requête.
Il y a forcément un truc…
Les sortilèges employés sont généralement, par ordre de complexité croissante :
1/ des index sur les bonnes colonnes : s’il manque un index dans une requête, votre base de données va devoir balayer toutes les colonnes, y compris les colonnes de texte. La différence de rapidité peut aller de 1 à 100. On visera en priorité les colonnes numériques (identifiant) ou de petite taille (ENUM)…
2/ réduire les données renvoyées par les SELECT en ne gardant que les colonnes vraiment utiles. L’impact va se sentir sur la mémoire et (si votre serveur de Base de données est physiquement séparé du serveur applicatif) sur la charge du réseau
3/ découper une grosse requête en plusieurs petites : c’est utile quant vous avez des jointures qui démultiplient la quantité de données à ramener. Attention, 2 ou 3 requêtes ça va, mais 100 requêtes vont générer trop de temps de négociation. On ne mettra pas de requêtes à l’intérieur d’une boucle. On préférera d’abord avec une première requête générer une liste d’identifiants (1, 2, 3…) qui alimenteront ensuite la requête suivante.
4/ précalculer les données de compteurs (COUNT) : cela implique l’exécution de calculs complexes en amont et la sauvegarde des résultats pour une utilisation ultérieure. Par exemple, si votre application doit souvent afficher le nombre total d’événements pour un utilisateur donné, il peut être plus efficace de calculer cette information au moment où un événement est créé ou supprimé, plutôt que de compter tous les événements à chaque fois qu’une page est chargée. Cette approche peut réduire considérablement la charge sur votre base de données.
5/ utiliser une base de données NoSQL comme Elasticsearch : Les bases de données NoSQL sont conçues pour traiter de grandes quantités de données distribuées de manière efficace. Elasticsearch, par exemple, est une base de données orientée document qui est excellente pour la recherche en texte intégral et peut traiter de grandes quantités de données en temps réel. L’utilisation d’une base de données NoSQL peut améliorer considérablement les performances dans certaines situations, en particulier lorsque vous travaillez avec de grands ensembles de données. On indexera régulièrement les données présentes dans la base relationnelle SQL (la « source de vérité ») pour maintenir l’index NoSQL à jour.
Toutes ces solutions, nous les mettons en oeuvre régulièrement chez Improba, avec un « effet Waouh » toujours aussi frappant.
Il fallait qu’on vous le partage !

